From Monolithic Hive to Federated Datasets: What Uber’s 16K-Dataset, 10+ PB Zero-Downtime Move Teaches About Data Platform Maintenance at Scale
Centralized data warehouses tend to fail in the same way: one schema change, one overloaded metastore, or one “quick” migration turns into a platform-wide incident. Uber’s move to federate 16K datasets across 10+ PB—while preserving zero-downtime analytics—offers a practical modernization playbook for teams trying to evolve brittle data platforms without freezing development for quarters.
Centralized data platforms rarely collapse all at once—they degrade. A metastore gets slower each quarter, schema governance becomes a ticket queue, and migrations become “big bang” events scheduled around holidays.
Uber’s recent work to decentralize a monolithic Hive warehouse using a federation approach is a concrete example of what it takes to modernize at extreme scale: 16K datasets, 10+ PB of data, and a clear requirement: zero-downtime analytics. The story, covered by InfoQ, is less about a shiny new tool and more about maintenance discipline—how to upgrade foundational systems without pausing the business. (Source: InfoQ, “Uber’s Hive Federation Decentralizes 16K Datasets and 10+ PB for Zero-Downtime Analytics at Scale.”)
This post breaks down the migration patterns that matter for developers, platform engineers, and CTOs—especially those wrestling with brittle, centralized data platforms—and translates them into actionable strategies you can apply in your own environment.
Context: Why monolithic warehouses become liabilities
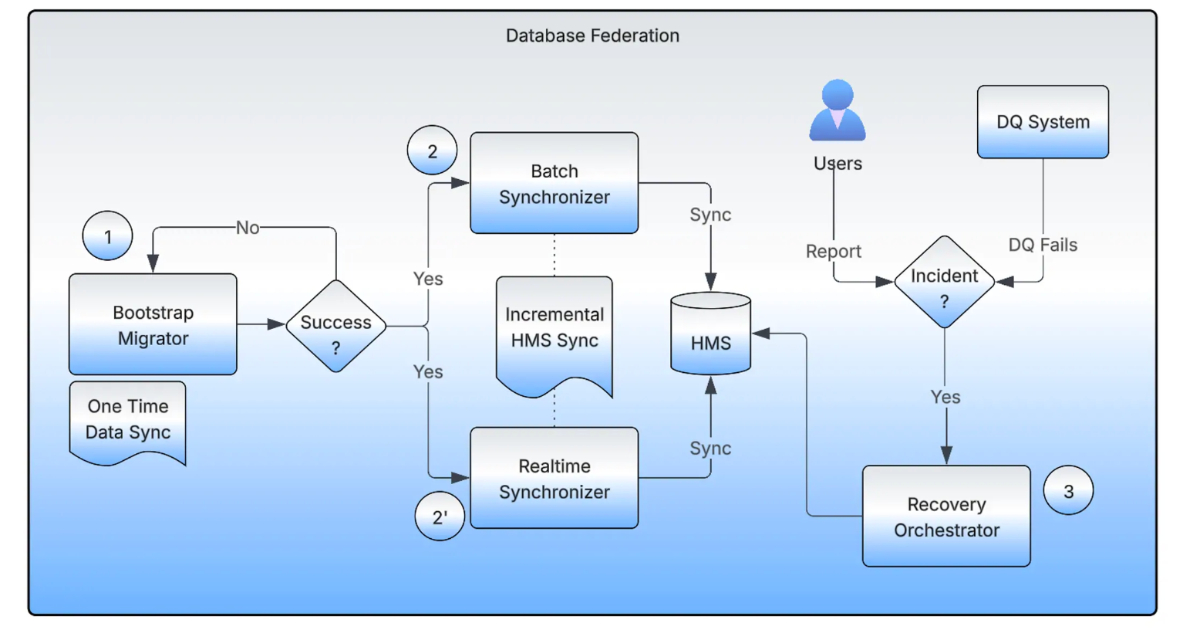
Most organizations start with a centralized warehouse because it’s the fastest route to shared analytics. Over time, success creates strain:
- A single control plane becomes a single failure domain. Changes to the metastore, access controls, and table formats ripple everywhere.
- Governance becomes a bottleneck. You get strong “central consistency,” but at the cost of team autonomy.
- Migrations become outages—or multi-quarter freezes. When every dataset shares the same substrate, platform upgrades require coordination across dozens (or hundreds) of stakeholders.
At Uber’s scale, those tradeoffs become existential. Their response—decentralizing with a federation layer—is notable because it targets the root cause: coupling.
InfoQ’s write-up frames this as a federation approach applied to Hive to achieve decentralized ownership while still providing unified analytics access. The key isn’t merely “splitting the warehouse”—it’s creating a stable interface that lets the platform evolve without forcing all producers and consumers to move in lockstep.
Main analysis: The patterns behind a zero-downtime federation migration
1) Treat federation as an “anti-corruption layer,” not just a router
In software modernization, an anti-corruption layer (ACL) is a boundary that prevents legacy constraints from infecting new systems. A dataset federation layer can play the same role.
Instead of telling every consuming workflow, dashboard, and notebook to migrate from Warehouse A to Warehouse B, the federation layer provides a consistent contract—so you can change implementations behind it.
Why this matters for maintenance:
- It reduces the blast radius of platform changes.
- It converts “rewrite everything” projects into “swap the backend” projects.
- It gives you a place to enforce compatibility rules and progressive rollout logic.
Actionable takeaway: Define the federation layer as a product with explicit SLOs and versioning. If it’s “just a thin proxy,” it will become the first casualty during incidents. If it’s a real interface boundary, it becomes your modernization lever.
2) Contract-first dataset interfaces: schemas as APIs
When a data platform is centralized, teams often rely on tribal knowledge: “This table is stable,” “That column is safe to use,” “This partition key is weird but don’t touch it.” Federation forces you to formalize.
A contract-first approach means:
- Schemas are versioned.
- Ownership is clear.
- Backward compatibility rules are explicit.
- Changes are validated automatically.
This is the data equivalent of API governance: the goal is not to prevent change, but to make change safe and observable.
How to apply it:
- Publish dataset contracts in a registry (even a simple Git-backed repo to start).
- Add CI checks for compatibility (e.g., disallow dropping columns without a major version bump).
- Require an owner and escalation path per dataset.
Maintenance outcome: You reduce the amount of “manual coordination” needed during platform upgrades because the compatibility surface is known.
3) Progressive cutovers: migrate consumers, not just storage
A frequent modernization failure mode is focusing on data movement (copying files, converting formats, re-partitioning) while underestimating consumer migration. The true downtime risk lives in the edges: query engines, BI tools, ad hoc notebooks, scheduled jobs, and cached assumptions.
Uber’s requirement for zero-downtime analytics implies progressive cutovers with strong parity checks—moving in stages, keeping compatibility, and enabling rollback.
A pragmatic progressive cutover plan usually includes:
- Dual-read / dual-write periods where feasible
- Shadow traffic (run queries against both backends and compare results)
- Canary cohorts (migrate a small set of consumers first)
- Kill switches (fast fallback to the prior path)
Actionable takeaway: Build a cutover runbook that is engineered like a production release: feature flags, staged rollout, automated verification, and clear rollback criteria.
4) Operational metrics that prevent “multi-quarter freezes”
Large platform migrations often fail because teams stop shipping. Everyone is “waiting for the migration,” so new features are deferred, and the platform becomes even more outdated by the end.
A federation strategy can reduce this freeze—but only if you measure the right things.
Consider metrics that track migration health without drowning teams in vanity KPIs:
- Coverage: % of datasets onboarded to federation
- Adoption: % of query volume routed through federation
- Parity: mismatch rate between old and new results (for shadowed queries)
- Performance: p95/p99 query latency deltas pre/post federation
- Reliability: error rates, timeouts, and throttling events
- Change velocity: mean time to onboard a dataset; mean time to migrate a consumer
Maintenance outcome: You get a dashboard that makes platform evolution visible and helps leadership avoid the “we’ll finish the migration before we do anything else” trap.
5) Decentralization doesn’t remove governance—it changes where it lives
Decentralizing 16K datasets doesn’t mean governance disappears. It means governance shifts from a centralized team approving everything to:
- Standard contracts
- Guardrails and automation
- Auditable ownership
- Platform-provided defaults
The federation layer can enforce org-wide invariants (security posture, lineage capture, access controls) while letting teams own lifecycle decisions for their datasets.
Actionable takeaway: Write down what must remain centralized (e.g., identity, permissions, audit logs, compliance controls) and what should decentralize (dataset evolution, performance tuning, lifecycle policies). Federation works best when these boundaries are explicit.
Practical implications for engineering teams (and how Vibgrate would frame it)
Modernization at this scale is ultimately a maintenance problem: upgrading a living system with thousands of dependents.
Here’s how to translate the Uber patterns—referenced in InfoQ’s coverage—into execution steps for your organization.
1) Start by mapping coupling, not by choosing new storage
Before you talk about Iceberg vs. Delta vs. Hudi (or object store layouts), inventory coupling:
- Which consumers assume a specific metastore?
- Which datasets are “shared primitives” used by hundreds of jobs?
- Where do implicit contracts exist (naming conventions, partition rules, timestamp semantics)?
This creates a migration graph. Your earliest wins should target low-coupling datasets and non-critical consumers to validate the federation approach.
2) Build the federation path like a product: SLOs, on-call, and error budgets
A federation layer is now in the critical path of analytics. Treat it like any other production platform:
- Define SLOs (availability, latency, correctness)
- Create clear runbooks
- Add tracing and audit logs
- Instrument end-to-end query routing
If you can’t explain “why this query was routed here” in a few clicks, incident response will be slow and trust will erode.
3) Make “dataset onboarding” a paved road
At 16K datasets, success depends on lowering the onboarding cost:
- Templates for contracts and metadata
- Self-service tooling
- Automated validation
- A clear maturity model (e.g., bronze/silver/gold readiness)
The goal is to avoid a migration that requires a central team to hand-hold every dataset.
4) Create upgrade-friendly interfaces: versioning and compatibility checks
To keep modernization from turning into a multi-quarter freeze, enforce compatibility at the boundary:
- Version schema contracts
- Add automated checks for breaking changes
- Provide deprecation windows
- Publish consumer impact reports
This is the same playbook used in high-scale API platforms—applied to data.
5) Plan for “correctness incidents,” not just downtime
Zero-downtime analytics isn’t only about uptime. It’s also about preventing silent correctness drift.
Include parity testing as a first-class feature:
- Diff results between backends for sampled queries
- Track mismatch rate and classify mismatches (expected vs. unexpected)
- Provide tooling for fast investigation (lineage, query plan capture, dataset version info)
Correctness observability is what lets you migrate without losing trust.
Conclusion: Federation is a maintenance strategy disguised as architecture
Uber’s federation-driven decentralization of Hive—spanning 16K datasets and 10+ PB, with a focus on zero-downtime analytics—isn’t just an impressive migration story. It’s a clear demonstration that platform evolution must be engineered like continuous delivery: contract-first interfaces, progressive cutovers, and operational metrics that keep change safe.
If you’re responsible for a centralized data platform that feels increasingly brittle, federation offers a way to modernize without betting the company on a single cutover weekend. The next step is to treat your data interfaces like APIs and your migrations like product rollouts—because at scale, maintenance is the product.
Source referenced: InfoQ, “Uber’s Hive Federation Decentralizes 16K Datasets and 10+ PB for Zero-Downtime Analytics at Scale” (April 2026): https://www.infoq.com/news/2026/04/uber-hive-decentralized-data/