Streaming-First CI “AI Steps” with WebSockets: Lower Latency, Fewer Timeouts, Better Logs, and Predictable Cost
AI steps inside CI/CD often fail for the same reasons as flaky integration tests: slow feedback, brittle timeouts, and poor observability. With OpenAI introducing a WebSocket-based execution mode aimed at reducing latency in agentic workflows, teams can redesign “AI steps” to be streaming-first—improving responsiveness, failure handling, and cost control without sacrificing reproducibility.
CI pipelines were built for deterministic tasks: compile, test, package, deploy. But as more teams embed “AI steps” into build/test/release and operations (triaging failures, proposing upgrades, generating migration diffs, writing release notes, or reviewing risky changes), the pipeline shape starts to look less like batch processing and more like an interactive session.
That mismatch is where most “flaky AI step” incidents come from: a long-running request hits a timeout, retries silently multiply cost, logs arrive too late to debug, and the whole job fails with little context. The good news is that the underlying execution model is catching up. OpenAI has introduced a WebSocket-based execution mode designed to reduce latency in agentic workflows—specifically targeting agent-style interactions where responsiveness and incremental progress matter (as reported by InfoQ).
This post breaks down what “streaming-first” means for CI, why WebSockets change the design constraints, and how to implement timeouts, retries, logs, and cost controls that make AI automation supportable in production—especially for software maintenance and modernization work.
Context: why CI “AI steps” feel flaky
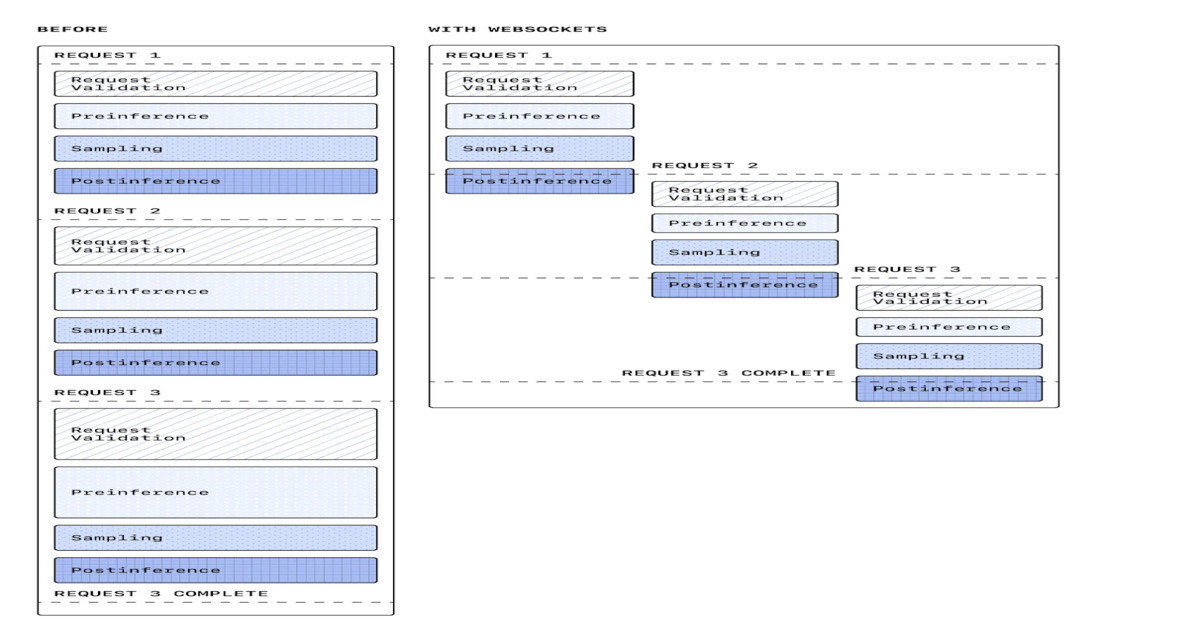
Many AI-in-CI integrations are built like this:
- Gather a big bundle of context (logs, diffs, test results, repo files).
- Send one large request.
- Wait.
- Parse one large response.
That pattern is natural when you’re calling an API over HTTP request/response. But it’s a poor fit for agentic workflows where the system may:
- ask for additional context (“show me the failing test output,” “open this file,” “what is the dependency tree?”)
- produce partial progress (a plan, then an action, then a patch)
- stream logs and intermediate reasoning that operators need to see
In practice, you get familiar failure modes:
- Timeouts and premature aborts: a single long request exceeds CI job limits or reverse proxy timeouts.
- Retries that amplify cost: CI retries re-run the same expensive step, often without deduplication.
- Opaque logs: engineers see nothing until the end, which makes it hard to debug or to trust outcomes.
- Non-reproducibility: re-running the same job yields different outputs because the interaction wasn’t captured as a sequence of events.
InfoQ’s coverage of OpenAI’s WebSocket-based execution mode points at the core issue: agent-style interactions need responsiveness and incremental progress, not just an eventual response. Lower latency isn’t only about speed—it’s about control.
What changes with WebSocket execution mode
With WebSockets, the integration becomes a live, bidirectional channel:
- The model can start emitting output immediately.
- Your system can stream additional context or tool results as they’re produced.
- You can enforce backpressure: if your CI runner or log collector can’t keep up, you can slow down ingestion rather than crash.
From a pipeline perspective, this is less like “call an API” and more like “run a subprocess with structured stdout/stderr.” That mental model unlocks better operational patterns.
Why lower latency matters in agentic workflows
Agentic steps are often gated by a tight feedback loop:
- propose a change → run tests → react to failures → adjust patch
If each iteration blocks on a long response, the whole loop becomes expensive and brittle. WebSocket streaming helps in three ways:
- Faster first token / first event: operators see immediate progress.
- Incremental results: you can decide to stop early if the step is going off-track.
- More resilient execution: you can recover from partial failure without restarting the entire step.
This aligns with broader “engineering at AI speed” conversations (also covered by InfoQ) where teams learn to shorten feedback cycles and keep automation observable.
Redesigning CI “AI steps” to be streaming-first
Treat your AI step like a long-running job with a stream of structured events. The objective is not merely to display a transcript—it’s to make the step operationally legible.
1) Streaming logs: separate “operator logs” from “artifact logs”
A streaming-first AI step should produce two log channels:
- Operator logs (live): short, continuous updates suitable for CI consoles (e.g., GitHub Actions, GitLab, Jenkins). Examples: “analyzing dependency graph…”, “proposed 3-file patch…”, “running unit tests…”.
- Artifact logs (persisted): a full event trace stored as an artifact (JSONL works well), including inputs, tool calls, partial outputs, and final results.
Why two channels?
- CI consoles have limits (line truncation, retention, redaction constraints).
- Post-incident analysis needs a stable artifact for reproducibility.
Actionable pattern: log structured events, not just text. For example:
phase_started: analyzetool_call: read_file(path)tool_result: read_file(success, bytes)partial_output: patch_diffdecision: abort(reason=budget_exceeded)
This design also supports modernization workflows: when the AI proposes an upgrade patch, the patch diff and the decision trail become part of the maintenance record.
2) Backpressure: don’t let streaming become a failure amplifier
Streaming can overwhelm downstream systems:
- CI log collectors
- internal event buses
- your own WebSocket client
Backpressure is your friend. Your “AI step runner” should be able to:
- pause consumption when buffers fill
- drop or compress low-value log events (e.g., repeated status updates)
- enforce an upper bound on in-flight tool results
Actionable pattern: implement a bounded queue for events and a “log sampling” policy:
- always keep errors
- sample verbose progress messages
- summarize long outputs (e.g., cap stack traces, store full content as artifact)
This turns WebSockets into a controlled stream instead of an uncontrolled firehose.
3) Timeouts: replace one big timeout with phase budgets
Batch HTTP calls encourage a single timeout like “120 seconds.” Streaming-first steps should use phase-based budgets:
- connect budget (e.g., 5s)
- first-event budget (e.g., 10s to see any progress)
- analysis budget (e.g., 60–180s depending on repo size)
- patch budget (e.g., 60s)
- test/run budget (e.g., bounded by CI job limits)
If a phase exceeds budget, you can:
- request a summary of progress so far
- gracefully abort with a clear reason
- emit partial artifacts (e.g., “here’s the proposed patch but tests weren’t run”)
This is a major reducer of “flaky AI step” incidents: instead of “step timed out,” you get “analysis phase exceeded 120s; returning partial plan and stopping.”
4) Retries: make them idempotent, resumable, and cost-aware
Retries are necessary—networks fail, CI runners restart. But naive retries double (or triple) spend.
A streaming-first AI step should define resume semantics:
- checkpoint at phase boundaries
- persist the event trace (inputs + tool results)
- on retry, replay the trace rather than re-fetching everything
Actionable pattern: design your step as a state machine:
INIT → CONTEXT_READY → ANALYZED → PATCH_PROPOSED → TESTED → DONE
On retry:
- resume from the last completed state
- re-run only the missing phases
- if inputs changed (new commit SHA, different lockfile), invalidate and restart cleanly
This approach is especially valuable for maintenance automation where changes are frequent and failures are common: dependency upgrades, security patching, and refactoring tasks should be resumable and auditable.
5) Cost controls: token budgets, early exits, and “stop-the-bleed” mechanisms
Lower latency is great, but streaming can also make it easier to spend continuously unless you set hard limits.
Implement cost controls at three levels:
a) Per-step budgets
Define a maximum spend (or token budget) per CI job, per repo, or per PR. If the step crosses the limit, stop and emit:
- a partial summary
- the point of failure
- next recommended action
b) Incremental “value checks”
Don’t wait until the end to decide if the step was worth it. Examples:
- If the model can’t identify the failing test within N seconds, abort and ask for human input.
- If the upgrade touches more than N files, require manual approval.
c) Deduplicate repeated work
Cache expensive context building:
- dependency graphs
- SBOMs
- lint/test summaries
In a modernization platform like Vibgrate, this caching is a force multiplier: maintenance automation becomes predictable when you reuse computed context across runs.
Practical implications for engineering teams
Moving to WebSockets isn’t just an SDK change; it’s a pipeline design change.
Observability: treat AI steps like production services
If an AI step can change code, it deserves production-grade telemetry:
- event traces as artifacts
- metrics: time-to-first-event, phase durations, retry counts, abort reasons
- spend metrics correlated to repo, branch, and workflow type
This supports the “verification over trust” mindset increasingly emphasized in software supply chains: don’t trust an AI patch because it sounds right—verify with tests, policy checks, and auditable traces.
Reproducibility: capture interactions, not just outputs
For maintenance and modernization, reproducibility is everything. A patch that can’t be explained or replayed becomes a long-term liability.
Streaming-first design helps by capturing:
- every tool call and result
- the exact diff proposed
- the gating checks performed
You can then answer: “Why did this change happen?” and “Can we recreate it on a new version?”
Failure handling: graceful degradation beats hard failure
A mature AI step does not have only two outcomes (success/fail). It can degrade:
- return a diagnosis without a patch
- return a patch without tests
- return a plan and required human inputs
This keeps CI moving while preserving safety.
A streaming-first blueprint for CI “AI steps”
If you’re implementing this now, aim for these building blocks:
- WebSocket session manager with reconnect + resume support
- Event schema (JSON) for logs, tool calls, and results
- Phase state machine with checkpoints
- Budget enforcer (time + cost)
- Artifact exporter (event trace + patch diff + summaries)
- Policy gates (file touch limits, approval thresholds, test requirements)
Even if you don’t adopt every component immediately, designing toward them prevents the common trap: a brittle “AI step” that becomes an always-red pipeline liability.
Conclusion: WebSockets push CI automation from batch to interactive
InfoQ’s report on OpenAI’s WebSocket-based execution mode highlights a shift toward lower-latency agentic workflows—exactly the kind of interaction pattern CI “AI steps” have been faking with long-running HTTP calls. For engineering leaders, the opportunity isn’t just faster outputs; it’s a more controllable, observable, and supportable automation layer.
Teams that redesign pipelines to be streaming-first—phase budgets, resumable retries, structured logs, backpressure, and cost guardrails—will see fewer flaky incidents and more trustworthy maintenance automation. As modernization work accelerates (dependency upgrades, platform migrations, security patches), these patterns turn AI from a demo into durable infrastructure.
Source: InfoQ, “OpenAI Introduces Websocket-Based Execution Mode to Reduce Latency in Agentic Workflows” (May 2026): https://www.infoq.com/news/2026/05/openai-websocket-responses-api/